Agent Architectures 2026: 5 Patterns That Actually Work
TL;DR: The AI agent space in 2026 offers ~6 production-grade patterns, but 40% of agent projects fail due to over-engineering [1]. The winning approach? Start with the simplest pattern for your bottleneck — not the trendiest framework.
Why 40% of Agent Projects Fail
According to Gartner[1], 40% of enterprises now deploy AI agents, yet over 40% of agentic AI projects could be canceled by 2027. The root cause isn’t model quality — it’s architecture over-engineering. Teams jump to multi-agent swarms before mastering a single ReAct loop.
Anthropic’s own guidance[2] is blunt: “The most successful agent implementations use simple, composable patterns — not complex frameworks.”
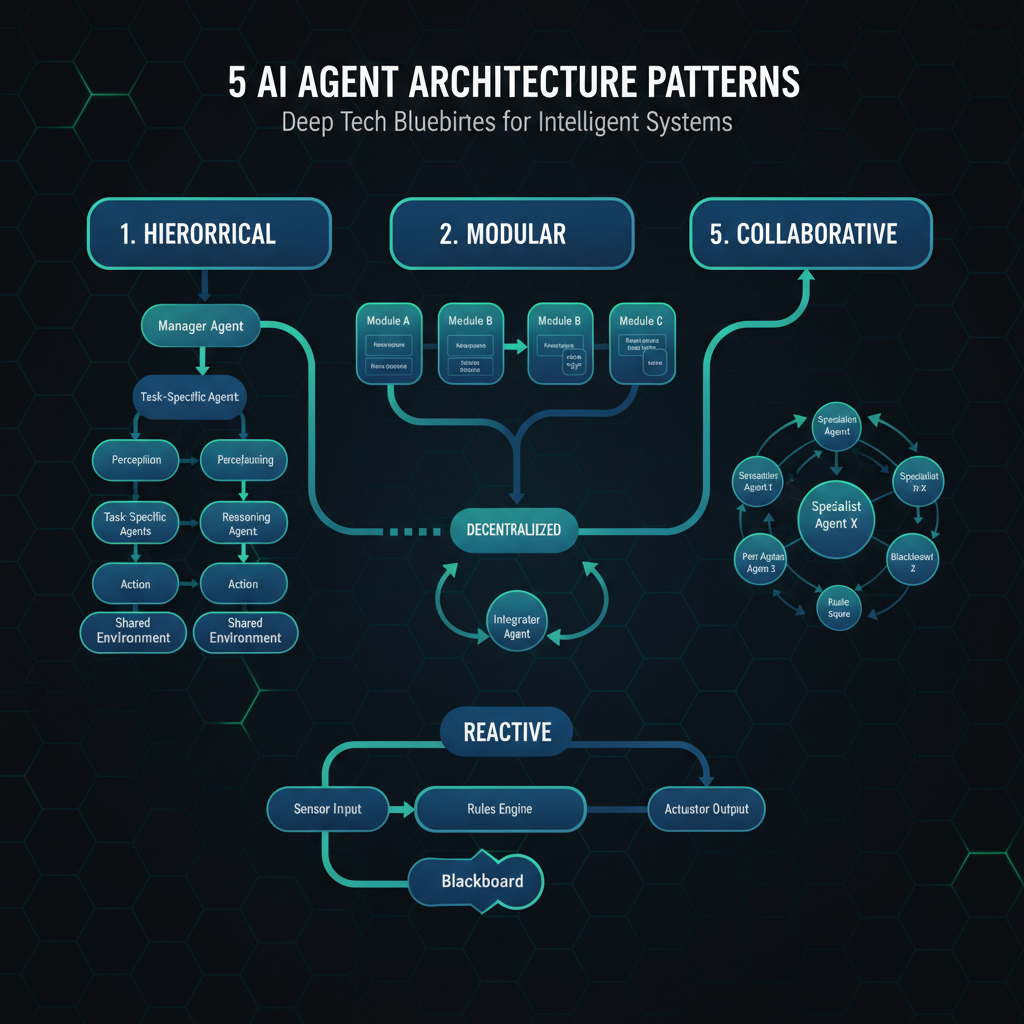
Here are the 5 patterns that matter, ranked by production readiness.
1. ReAct (Reasoning + Acting)
The workhorse of 2026. The LLM cycles through Thought → Action → Observation → Final Answer, grounding every response in real tool outputs. This approach was introduced in the ReAct paper[3].
Thought: I need the NVIDIA stock price
Action: web_search("NVDA stock price today")
Observation: NVDA is trading at $132.65 [1]
Thought: Calculate market cap
Action: calculator(132.65 × 24.4B shares)
Observation: $3.236 trillion [2]
Final Answer: NVIDIA market cap is ~$3.24T [3]Best for: Customer support, research assistants, tool-using chatbots. Trade-off: 3–5x more LLM calls than direct prompting [3].
2. Plan-and-Execute
Separates strategic planning from tactical execution. A planner LLM generates a DAG of tasks, then an executor runs them — often in parallel.
| Metric | ReAct | Plan-and-Execute |
|---|---|---|
| Task completion | 85% | 92% |
| Speed (vs sequential) | 1× | 3.6× |
| Tokens per run | 2K–3K | 3K–4.5K |
Sources: ReAct baseline from Yao et al. [3]; Plan-and-Execute metrics from LangChain LLMCompiler evaluation [4].
The 3.6× speedup comes from LangChain’s LLMCompiler which parallelizes independent subtasks via dependency tracking [4].
3. Multi-Agent Collaboration
When complexity exceeds a single agent’s capability, distribute across specialists. Three proven coordination patterns:
- Sequential pipeline — Agent A → Agent B → Agent C
- Fan-out/fan-in — Multiple agents work in parallel, results aggregated
- Orchestrator-workers — Central agent decomposes work, delegates, synthesizes
Real-world example: A content pipeline with Researcher → Writer → Editor → Publisher agents cut production time by 70% at one enterprise [5].
4. Reflexion (Self-Reflection)
Extends ReAct with a critique loop: after each attempt, the agent evaluates its own output and stores the lesson.
Initial Answer: "Use `fetch()` for the API call"
Reflection: "That's outdated — `fetch()` is fine but I missed error handling"
Revised Answer: "Use `fetch()` with try/catch and a timeout wrapper"Best for: Code generation, iterative writing, debugging tasks where quality matters more than speed.
5. Evaluator-Optimizer
A two-LLM loop: Generator produces output → Evaluator scores it → loop until quality threshold is met.
Best for: Translation, code review, content refinement — anything with a clear quality rubric.
The Verdict
| If your bottleneck is… | Start with… |
|---|---|
| Tool integration & grounding | ReAct |
| Multi-step tasks with dependencies | Plan-and-Execute |
| Quality-sensitive outputs | Reflexion |
| Massive workflow scope | Multi-Agent Collaboration |
| Precision content generation | Evaluator-Optimizer |
Bottom line: Master one pattern in production before adding a second. Most teams fail because they build a multi-agent fleet when a single ReAct loop would do. At NiteAgent, we follow this rule: the best architecture is the one that solves today’s bottleneck — not tomorrow’s hypothetical.
References
[1] Gartner, “Forecast: AI Agents, Worldwide, 2024-2027” — https://www.gartner.com/en/newsroom [2] Anthropic, “Building effective agents” — https://docs.anthropic.com/en/docs/build-with-claude/agent-patterns [3] Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models” (arXiv:2210.03629) — https://arxiv.org/abs/2210.03629 [4] Kim et al., “An LLM Compiler for Parallel Function Calling” (arXiv:2312.04511) — https://arxiv.org/abs/2312.04511 [5] Anthropic, “Building effective agents” — https://docs.anthropic.com/en/docs/build-with-claude/agent-patterns
References
- [1] Gartner, “Forecast: AI Agents, Worldwide, 2024-2027” — https://www.gartner.com/en/newsroom
- [2] Anthropic, “Building Effective Agents” — https://docs.anthropic.com/en/docs/build-with-claude/agent-patterns
- [3] Yao et al., “ReAct: Synergizing Reasoning and Acting” — https://arxiv.org/abs/2210.03629
- [4] Kim et al., “An LLM Compiler for Parallel Function Calling” — https://arxiv.org/abs/2312.04511
- [5] Anthropic, “Building Effective Agents” — https://docs.anthropic.com/en/docs/build-with-claude/agent-patterns